Quick Insights:
- Problem: Off the shelf large language models are powerful, but it is not obvious how well they adapt to narrow creative domains such as horror stories or fairy tales. We wanted to see how fine tuning changes style and sentiment for these genres.
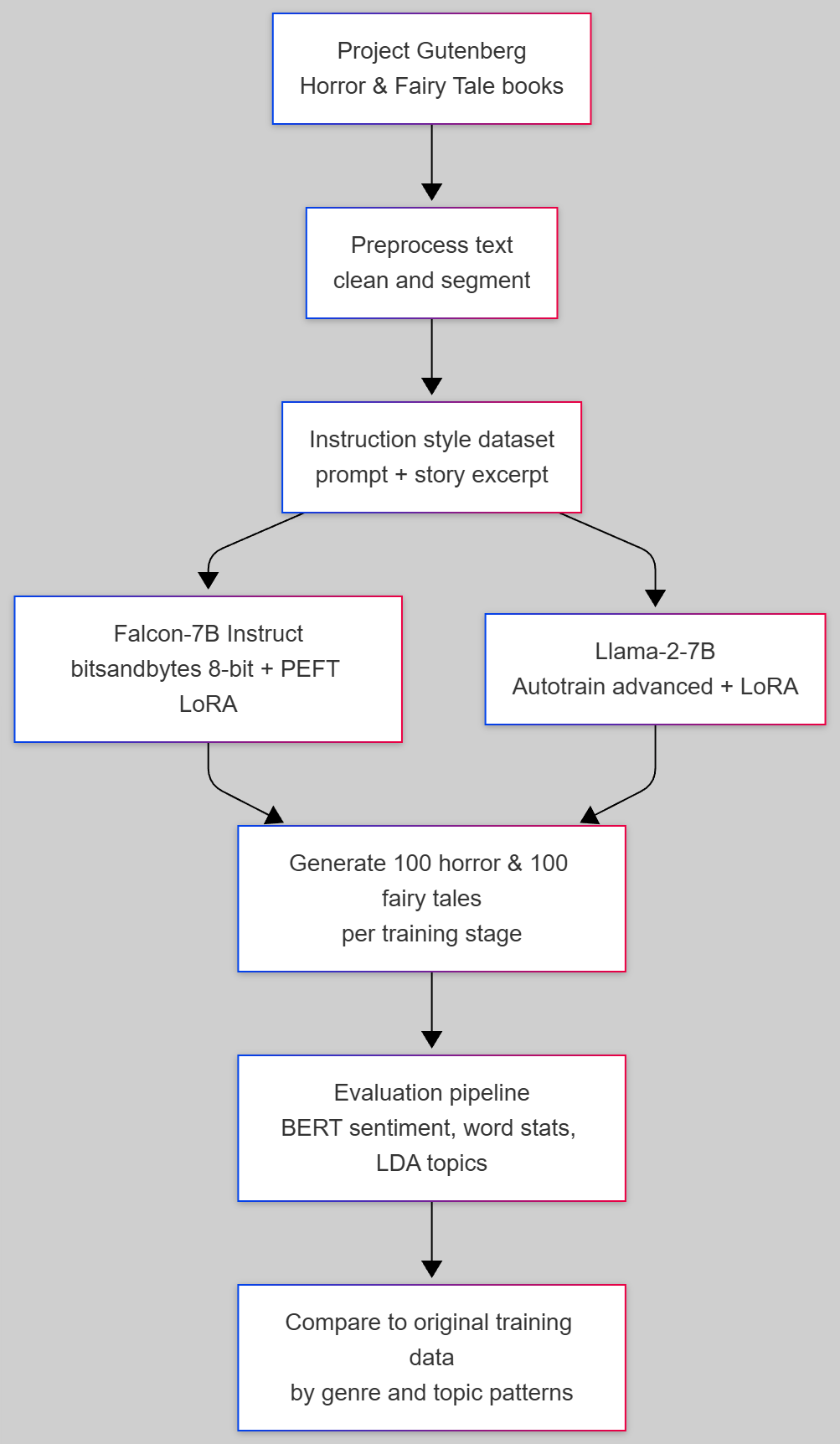
- Solution: Trained Falcon 7B and Llama 2 7B on horror and fairy tale books using parameter efficient fine tuning and LoRA. Built an evaluation pipeline that compares generated stories with the training distribution using sentiment analysis, word statistics and topic modeling.
- Result: Falcon tuned with PEFT and LoRA, updating only about 4.7 million trainable parameters (around 0.13 percent of the model), produced stories whose sentiment and topical patterns were closer to the training data than Llama 2 7B, especially for horror. We generated 100 stories per scenario to compare original data, base models and multiple fine tuning stages.
Introduction
This project explores how open source large language models can be adapted for a focused creative task. We targeted two genres, horror and fairy tales, and two models, Falcon 7B Instruct and Llama 2 7B. The goal was to understand both how to train these models on a small domain specific dataset and how their behavior changes after fine tuning.
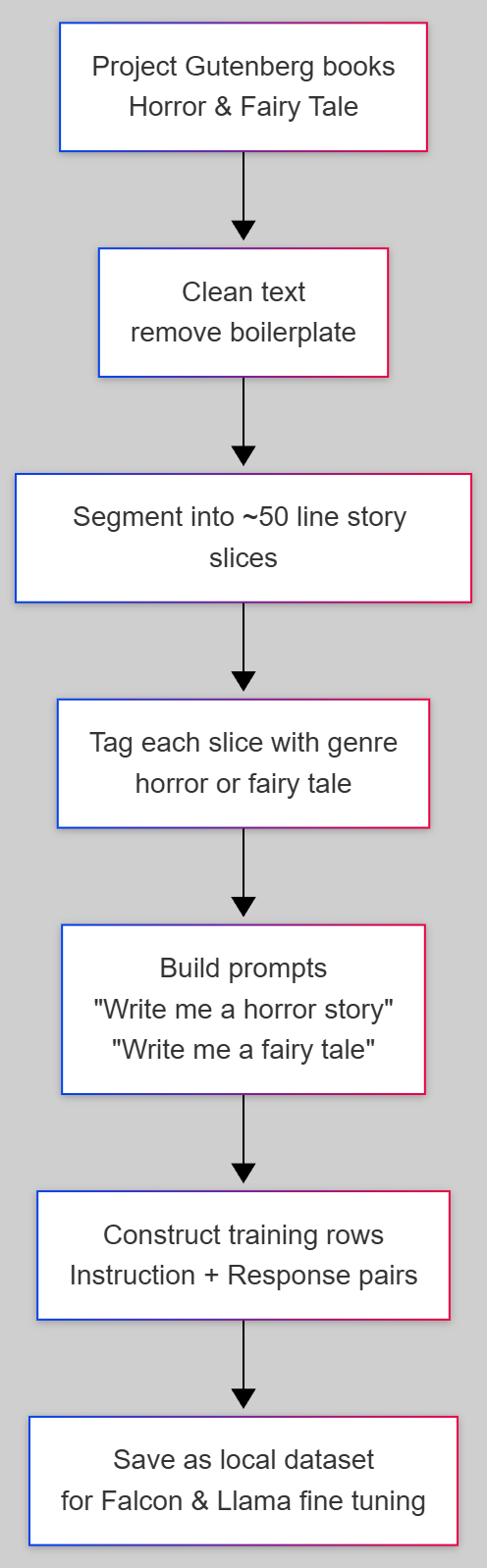
We used Project Gutenberg, a public domain digital library of books in plain text format, as the data source. Books were cleaned and converted into instruction style prompt and response pairs. A typical training row has a prompt such as "Write me a horror story" or "Write me a fairy tale" and a roughly 50 line excerpt from a matching story as the response. This structure lets us reuse the same dataset across different instruction tuned models.
- Falcon 7B was loaded in 8 bit mode with bitsandbytes and fine tuned using PEFT and LoRA while freezing the base weights.
- Llama 2 7B was fine tuned using Autotrain advanced with the same instruction style dataset and comparable settings for a fair comparison.
- For each configuration, we generated up to 200 tokens per story and ran a shared evaluation pipeline across all story sets.
Dataset and Prompt Formatting
The dataset started as raw text files from Project Gutenberg for both genres. We removed boilerplate, normalized the content and split each book into self contained story slices. Each slice was tagged with its genre and turned into an instruction style training example.
- Books were segmented into roughly 50 line excerpts to keep stories coherent while still practical for training.
- Each segment used a genre specific prompt such as "Write me a horror story" or "Write me a fairy tale" with the segment as the response.
- The resulting dataset could be fed to both Falcon and Llama models without changing the format, which made the comparison more direct.
End to End LLM Pipeline
Sample generated story (Horror, Falcon 7B tuned)
"It is the story of the old man who lived alone in the woods,"
answered the boy. "He had no friends, and no one ever came to
visit him. He was very lonely, and one night he heard a voice
calling him. He opened the door, and there stood a tall,
gray-haired man, with a white beard. He said he had come to take
him away, and that he was to go to a better place than he had ever
been to before. He took the old man by the hand, and led him away
into the woods. They walked all night, and when they reached a
little lake, the man said to the old man, "Now, I am going to tell
you a story. You have heard of the devil, and you know that he lives
in hell."This sample shows how the tuned Falcon model adopts genre appropriate setting, character choices and mood for horror stories using the instruction based training.
Evaluation and results
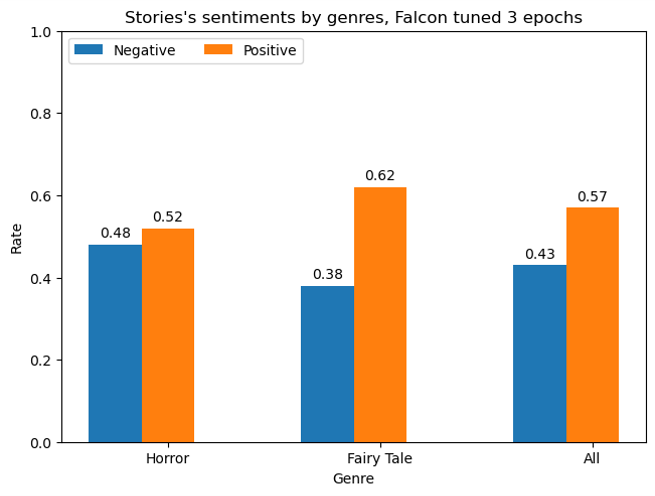
We compared original data, base models, partially trained Falcon, Falcon tuned for three epochs and Llama 2 after one epoch. For each configuration we generated 100 stories and analyzed them with three complementary methods.
-
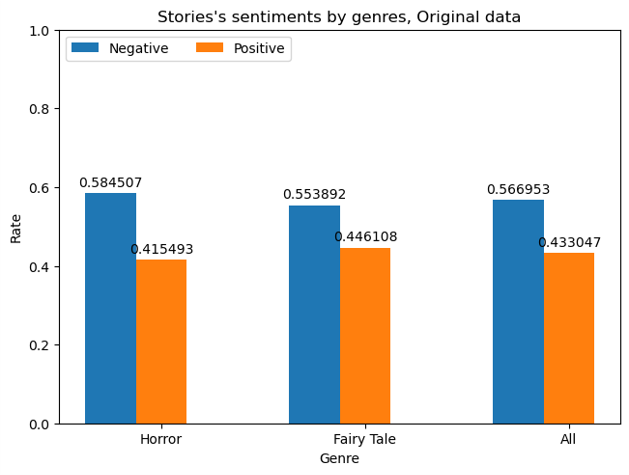
Sentiment analysis by genre:
Used a BERT based sentiment classifier on the last 512 tokens of each story to measure the proportion of positive and negative endings for horror, fairy tales and all stories combined. -
Top positive and negative words:
Counted curated positive and negative words to see which sentiment carrying terms dominated each model and how that differed from the original data. -
Topic modeling with LDA:
Ran LDA on each story set and inspected topics to check whether fairy tales preserve royalty and family themes and horror stories retain darker imagery such as night, ghosts or forests.
Overall, Falcon tuned with PEFT and LoRA moved closer to the training distribution. Horror stories from Falcon were more likely to have negative endings and fairy tales more likely to have positive tone, while Llama 2 often pushed both genres toward more positive outcomes.
Key outcomes and learnings
This project combined modern LLM tooling, parameter efficient fine tuning and lightweight evaluation methods into a single workflow for creative text generation.
- Structured an instruction style dataset from public domain books and reused it across different models and training configurations.
- Used PEFT and LoRA to fine tune only 0.13 percent of Falcon 7B parameters, making experimentation feasible on limited hardware.
- Designed an evaluation pipeline that blends sentiment analysis, word statistics and topic modeling instead of relying on a single score.
- Observed that Falcon 7B was better suited for this creative story task, while Llama 2 behaved more like a generic instruction follower and often softened the tone of horror stories.
- Identified next steps such as scaling the dataset, trying different prompts and testing newer base models for more controllable genre specific generation.