Quick Insights:
- Problem: Build a classical computer vision pipeline that can recognize multiple everyday objects in real time from a webcam feed, without relying solely on heavyweight deep learning models.
- Solution: Implemented custom Otsu thresholding, morphological cleanup and connected-component segmentation, then computed a compact feature vector per object (Hu moments, oriented bounding box ratio, percent fill and principal-axis angle) and classified with distance-based nearest neighbour and cosine similarity, with support for adding new objects interactively.
- Result: System recognized up to 13 object categories in live video and maintained rotation- and scale-robust predictions, backed by confusion-matrix evaluation and an optional DNN-embedding classifier for comparison.
Introduction
ShapeSense is a real-time 2D object recognition system built as part of a computer vision course. The goal was to design a full pipeline from raw video frames to predictions using classic vision techniques rather than end-to-end deep networks.
The system focuses on dark objects on a light background (e.g., mug, glove, passport, watch) placed on a workspace. From each frame, we threshold, clean, segment and then compute custom features that are invariant to translation, scale and in-plane rotation. These features are stored in a CSV database and used for nearest-neighbour classification in real time.
- Supports 13 trained object classes with room to add more
- Operates on a live video stream, not just static images
- Offers both classic k-NN style classifier and a DNN-embedding mode for comparison
- Includes an interactive unknown-object registration and a dynamic confusion matrix for evaluation
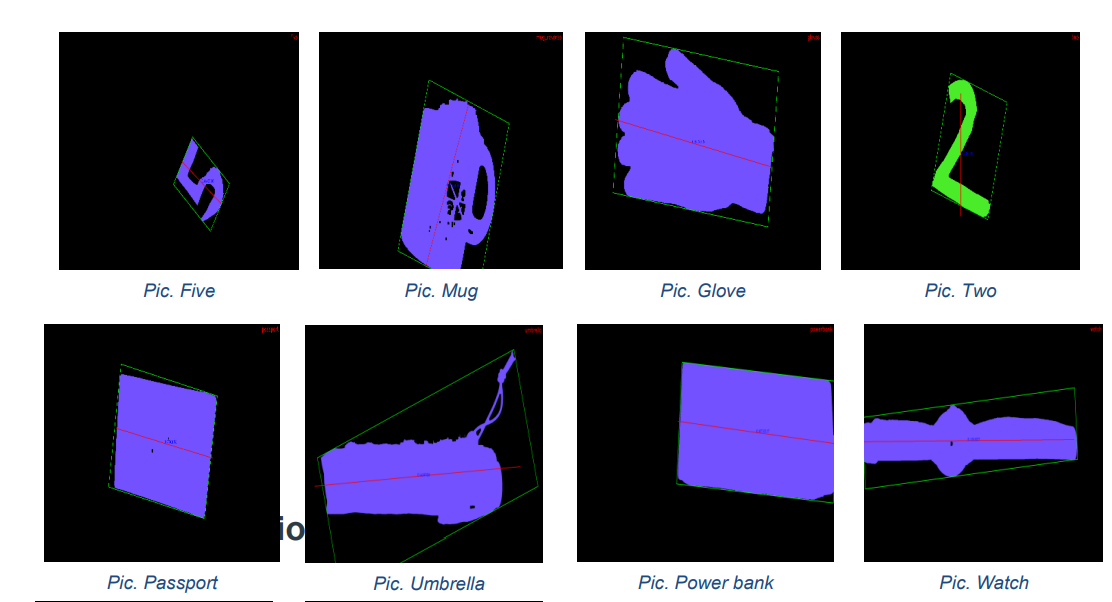
Sample Inputs and Feature Visualization
The examples below show a subset of the objects used for training and how they appear after segmentation and feature computation.


Pipeline & Feature Design
The full pipeline is implemented in C++/OpenCV and runs per frame on live video. Each step is designed to make the final feature vector robust to translation, scaling and rotation.
- Custom Otsu Thresholding: Gaussian blur followed by manually implemented Otsu to separate foreground objects from background.
- Morphological cleanup: custom dilation and erosion matrices to remove noise and unify object blobs.
-
Segmentation:
connectedComponentsWithStatsto extract candidate regions above a minimum area threshold. -
Feature vector per region (7D):
– 5 Hu moments (scale / rotation / translation invariant)
– oriented bounding box height–width ratio
– percent of box area filled by the object - Orientation robustness: principal axis of least central moment is computed and drawn in red; the features are monitored while rotating the object to verify stability.
Representative Code Snippet
// Extract major region and compute moments
Moments mu = moments(regionMask, true);
// Compute Hu moments (rotation/scale invariant)
double hu[7];
HuMoments(mu, hu);
// Compute oriented bounding box and fill ratio
RotatedRect box = minAreaRect(regionPoints);
float boxRatio = box.size.height / box.size.width;
float fillPercent = contourArea(regionPoints) /
(box.size.height * box.size.width);
// Build 7D feature vector for this object
std::vector<double> features = {
hu[0], hu[1], hu[2], hu[3], hu[4],
boxRatio, fillPercent
};
Classification & Evaluation
With the feature vectors in place, recognition is done with simple, explainable methods and evaluated via confusion matrices.
- Nearest-neighbour classifier: scaled Euclidean distance over the 7-dimensional feature vector, using a CSV file as the feature database; if the minimum distance is above a threshold, the object is labeled as unknown.
- Unknown object support: when an unknown is detected, the user can press a key to provide a label; the new feature vector is then appended to the CSV so future frames recognize it.
- DNN comparison mode: an optional mode uses deep embeddings and cosine similarity, providing a contrast with the classic nearest-neighbour approach on shape descriptors.
- Confusion matrix: a dynamic confusion matrix is built in real time by letting the user confirm ground-truth labels and logging predicted vs. true classes.
- Real-time performance: all processing is done on live video, not just offline images, so users can move and rotate objects to see how the recognizer behaves.
This project deepened my understanding of how a classical 2D object recognition system can be engineered end-to-end, and how it compares in practice to DNN-based approaches on small, controlled datasets.