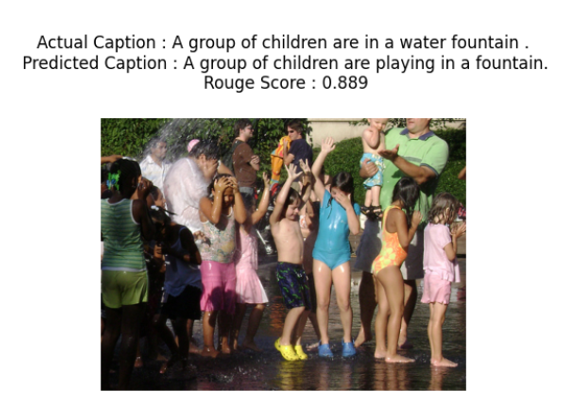

Quick Insights:
- Problem: Given an input image, generate a natural-language caption that captures the main scene, actors and action – and compare how classic CNN-RNN architectures stack up against modern transformer-based encoder–decoder models.
- Solution: Implemented and trained three variants: CNN-RNN with Inception v3 + 2-layer LSTM decoder, CNN-RNN with attention over visual features, and a ViT-GPT2 model fine tuned via Hugging Face as a unified encoder–decoder. All models were trained on the same caption dataset and evaluated under a common pipeline.
- Result: Attention improved semantic coverage over the baseline, and the ViT-GPT2 model achieved the best performance with an average ROUGE score of 0.45 and the lowest test loss (2.78), while also handling longer, more descriptive captions.
Introduction
This project investigates different neural architectures for image captioning, from classic CNN-RNN pipelines to transformers. The goal was to move beyond “toy examples” and build a training + evaluation loop that makes it easy to benchmark ideas under the same data, metrics and preprocessing.
We started with a strong baseline using pre trained
Inception v3 as a feature extractor and a 2-layer
LSTM decoder trained with teacher forcing. We then added an
attention mechanism over the image features, and finally replaced the
entire stack with a ViT-GPT2 encoder–decoder initialized from
Hugging Face checkpoints and fine tuned using
Seq2SeqTrainer.
- Tokenizer and vocabulary built from training captions
- Images augmented via random cropping and normalization
- Teacher forcing ratio set to 1.0 during training, with scheduled sampling considered as future work
- Evaluation performed with ROUGE scores and test cross-entropy loss
CNN-RNN Baseline
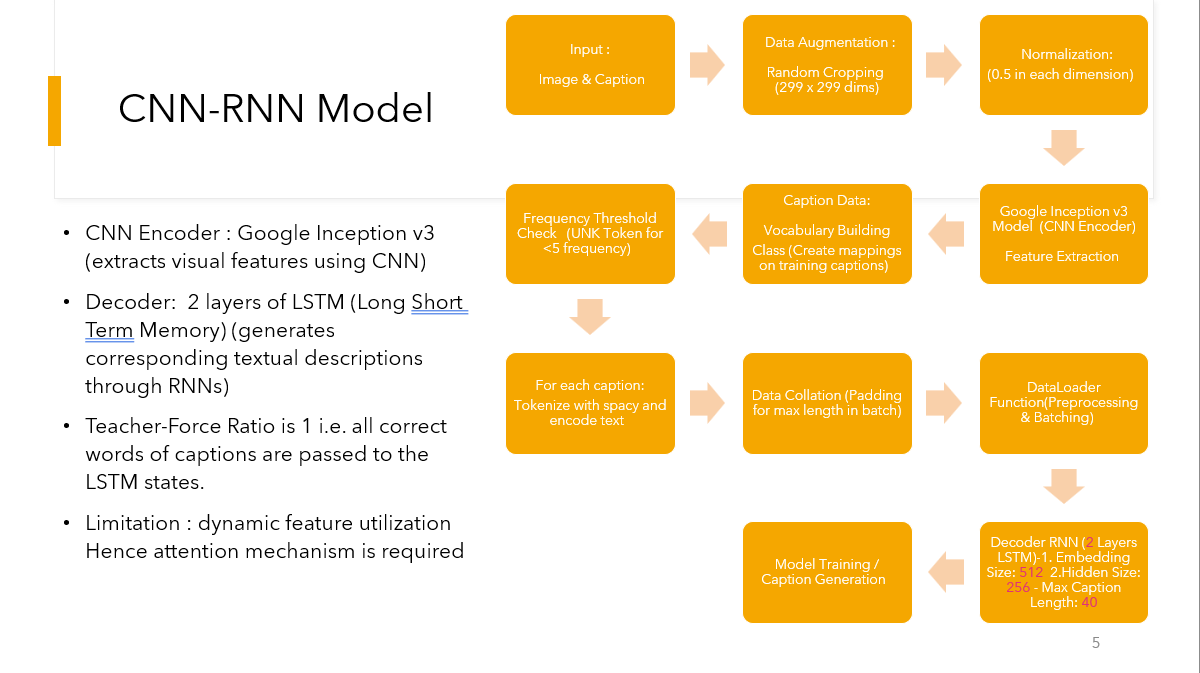
The baseline model extracts a fixed visual embedding from Inception v3 and feeds it as the initial hidden state to a 2-layer LSTM that predicts the caption token by token.
- Inception v3 encoder frozen during early epochs
- LSTM hidden size and embedding size chosen to balance capacity and training time
- Achieved an average ROUGE score of 0.336 with a test loss of 4.82 after 100 epochs (~7 hours of training)
- Captures broad scene information but often misses finer details such as small objects or modifiers
Adding Attention on Visual Features
To improve detail capture, we extended the baseline with an attention mechanism that lets the decoder focus on different spatial regions of the image as each word is generated.
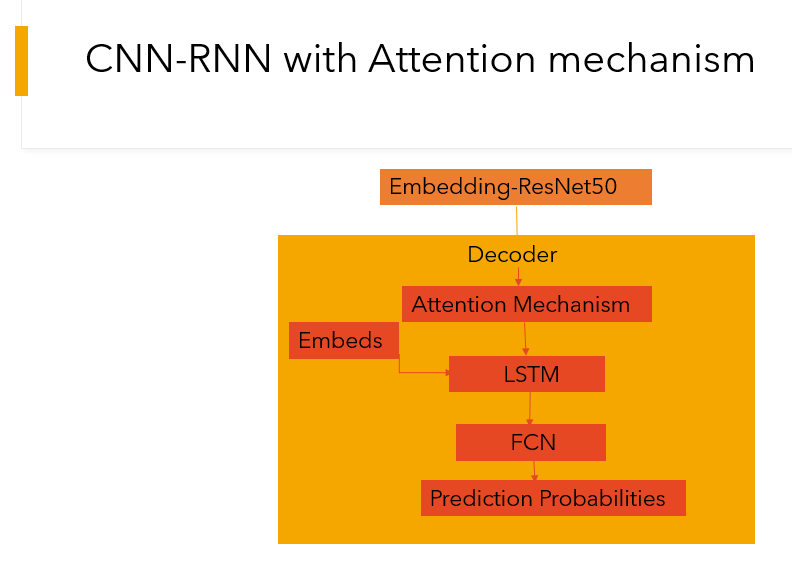
- Attention weights computed over feature maps from the CNN encoder
- Decoder receives both previous hidden state and attended visual context at each step
- Improved the average ROUGE score to 0.41 and reduced test loss to 3.09 with similar training time (~8 hours)
- Qualitatively, captions better reflected key objects and actions, especially when multiple entities are present
ViT-GPT2 Encoder–Decoder

The final model uses a Vision Transformer (ViT) as the image encoder and GPT-2 as the text decoder. Both components are initialized from pre trained Hugging Face models and jointly fine tuned on the captioning dataset.
- ViT processes 224×224 images into patch embeddings passed through transformer layers
- GPT-2 decoder attends over both text and image embeddings, making it more expressive for long captions
- Achieved the best average ROUGE score: 0.45 and lowest test loss: 2.78
- Captured richer spatial relationships and nuanced details (e.g., “group of children playing in a fountain” rather than generic “children outside”)
Results & Model Comparison
The table below summarizes the three approaches under the same training schedule. ViT-GPT2 offers the best caption quality while keeping training time reasonable thanks to pre training.
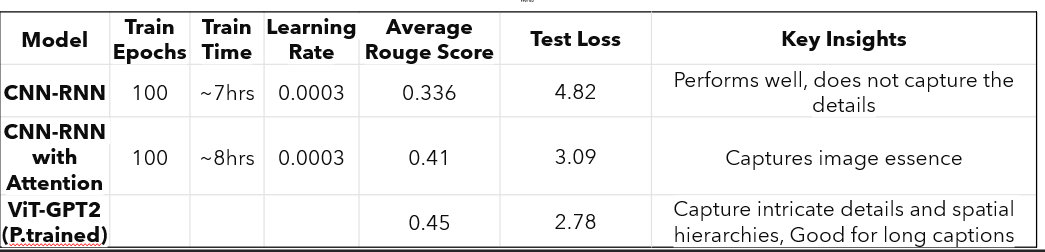
- CNN-RNN: strong baseline, underfits fine details and relationships between objects.
- CNN-RNN + Attention: better at focusing on key regions, especially for multi-object scenes.
- ViT-GPT2: most expressive model; excels at longer, more descriptive captions and aligns best with human-written references.
Key Takeaways
This project provided a practical comparison between classic and transformer-based captioning systems under a controlled setup. It also reinforced the importance of clean preprocessing, consistent evaluation, and strong baselines.
- Built a reusable training + evaluation loop that can plug in different encoder–decoder architectures with minimal changes.
- Saw how attention mechanisms systematically improve coverage of salient objects compared to plain CNN-RNN models.
- Confirmed that leveraging pre trained ViT and GPT-2 gives a clear boost in caption quality, especially for complex scenes.
- Deepened understanding of sequence modeling, vision transformers and how to read and compare metrics like ROUGE and test loss in a multi-model experiment.